
Mining pools allow individual miners to smooth out their income streams over time. Reducing income uncertainty and making returns predictable was the impetus for creating mining pools in the first place and enables smaller players to survive the volatility. From Wikipedia:
Mining in pools began when the difficulty for mining increased to the point where it could take centuries for slower miners to generate a block. The solution to this problem was for miners to pool their resources so they could generate blocks more quickly and therefore receive a portion of the block reward on a consistent basis, rather than randomly once every few years.
The larger the mining pool, the more predictable the returns. As we saw in Get Poisson Pilled mining Bitcoin is volatile, with hash rate estimates for the entire network requiring a +/-20% confidence bound per day. Volatility is even higher for individual mining pools because they comprise a subset of the network, finding fewer blocks and thus having a lower Poisson λ.
Again from Get Poisson Pilled:
The precision of a hash rate estimate can be improved by playing with two different levers, but both basically amount to increasing the sample size.
Use a longer time period: you observe more blocks and have a larger sample size to make an estimate from, reducing variance in your estimate
Use a higher frequency event: you can increase your sample by using mining pool shares (which occur proportionally to block production), again reducing the variance in your estimate
The larger the mining pool, the less volatile / more predictable the returns because finding a block becomes a higher frequency event.
The downside of larger mining pools is increased centralization. Mining pool operators construct the block template that individual miners hash, giving them power over which transactions appear in the block and the ability to censor transactions (see “OFAC compliant blocks”). Mining pool operators are also responsible for flagging for soft forks.
An individual miner can always leave a pool if they disagree with the actions taken by a pool operator, but they will incur more income volatility if they move to a smaller pool.
We can quantify the tradeoff between mining pool size and income variance. The table below shows the Coefficient of Variation (Standard deviation divided by mean, “the extent of variability in relation to the mean of the population”) for mining returns for various mining pool sizes (as measured in share of total hash rate) over various time periods. The higher the coefficient, the more volatile the returns (as measured in blocks found by the pool over the period).

To get an idea of current pool sizes, head over to btc.com/stats/pool. Antpool is currently the largest pool and has 15% of network hash rate. GHash.io famously accounted for 51% of network hash for a brief moment before dropping below that scary threshold.
If you were to mine in a pool with 1% of hash rate over a period of one day, the standard deviation of your expected returns would be a whopping 83% of the mean expected value. If we simulate a single day many times, the distribution of return profile (blocks found) looks like this across a couple different pool sizes:

As you can see, the distribution for (1%, 1 Day) bumps up against the left boundary where the pool finds 0 blocks in the day around 25% of the time. This drives the huge variance because it truncates the left tail of the distribution. If you are joining a pool, you want to make sure the pool is large enough, and the time horizon long enough, that you’re not hitting the zero-boundary of expected blocks found.
The CoV decreases as your time horizon increases from 1 day out to 1 year etc. This is the same distributions as above but for mining over 1 month instead of 1 day:
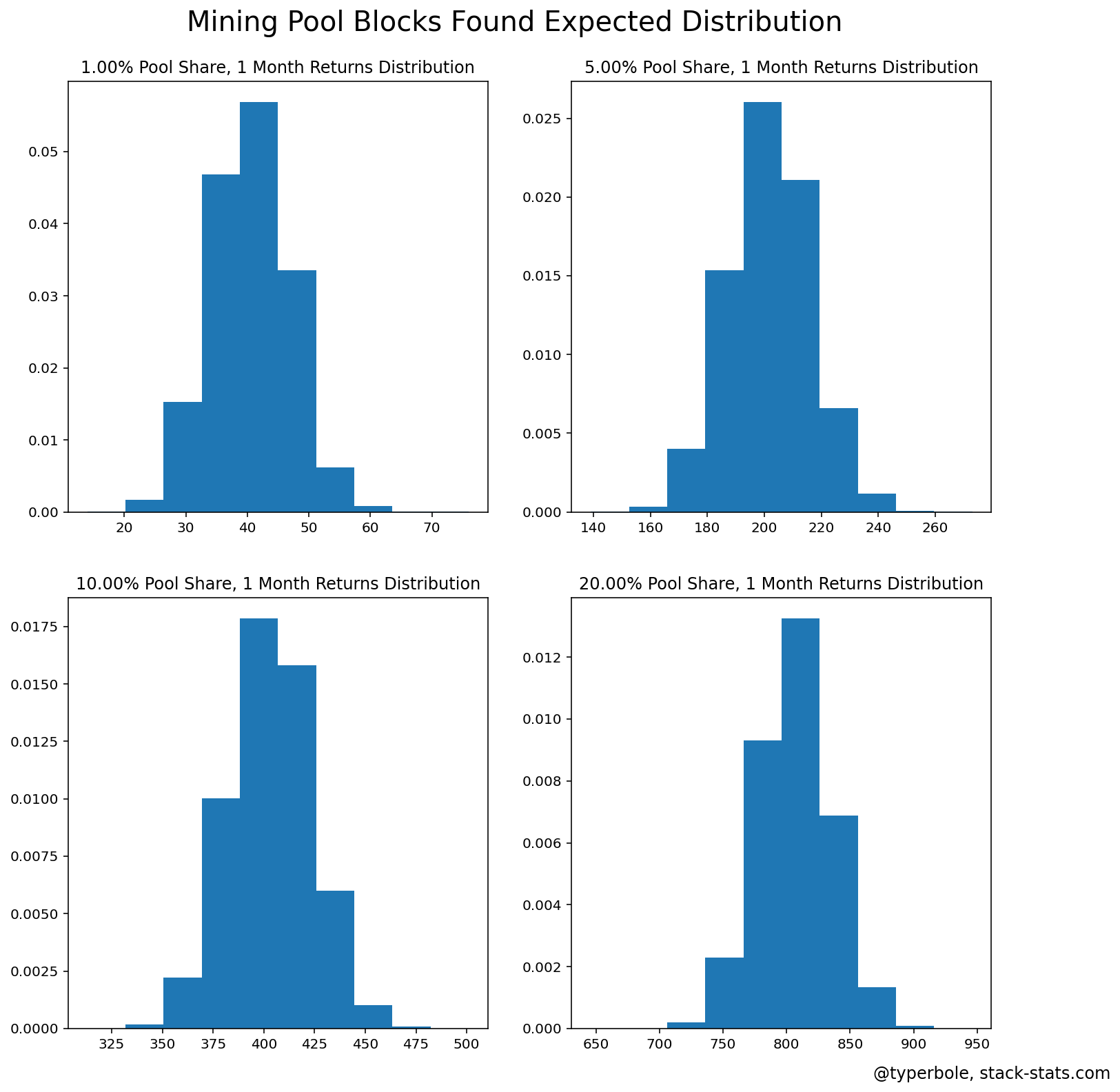
The 1% pool no longer bumps up against the zero-boundary, and the sample size is greater, so the CoV decreases from 83% in the 1-day sample to 15% in the 1 month.
Looking at the heatmap table above and comparing it to current pool sizes, pools in the dominant 5-15% share range will have tolerable returns volatility (<10% CoV) over any period greater than a few weeks. Of course this is already known since these pools exist and thrive outside the confines of this naive simulation.
Nevertheless it’s nice to validate that the gains from increasing pool size above say 10% are pretty marginal and won’t exert centralizing pressure. Having a handful of 5-15% sized mining pools seems to be a pretty stable equilibrium that balances overall decentralization and individual pool return stability.
Appendix
Code to generate the heatmap table:
import pandas as pd
import numpy as np
from tqdm import tqdm
import seaborn as sns
pool_sizes = []
for i in range(1, 10):
pool_sizes.append(i / 10000)
pool_sizes.append(i / 1000)
pool_sizes.append(i / 100)
for i in range(1, 20):
pool_sizes.append(i / 20)
pool_sizes = pd.Series(pool_sizes).drop_duplicates().sort_values()
data_out = []
for period_days in [1, 7, 14, 28, 90, 182, 365]:
expected_blocks = 6 * 24 * period_days
for pool_size in tqdm(pool_sizes):
samples = np.random.poisson(pool_size * expected_blocks, 100000)
mean, stdev = np.mean(samples), np.std(samples)
pct = stdev / mean
data_out.append({
'period_days': period_days,
'pool_size': pool_size,
'mean': mean,
'stdev': stdev,
'stdev_pct': pct
})
data = pd.DataFrame(data_out)
pivot = data.pivot(index='pool_size', columns='period_days', values='stdev_pct')
pivot['Pool Size'] = pivot.index
pivot.reset_index(drop=True, inplace=True)
cm = sns.light_palette("red", as_cmap=True)
(
pivot[['Pool Size', 1, 7, 14, 28, 90, 182, 365]].style
.format({
'Pool Size': '{:,.2%}'.format,
1: '{:,.2%}'.format,
7: '{:,.2%}'.format,
14: '{:,.2%}'.format,
28: '{:,.2%}'.format,
90: '{:,.2%}'.format,
182: '{:,.2%}'.format,
365: '{:,.2%}'.format})
.background_gradient(cmap=cm, subset=[1, 7, 14, 28, 90, 182, 365], axis=None)
.hide_index()
.set_table_attributes("style='display:inline'").set_caption('Days In Period')
)